dzone.com
/1 month ago
The Vector Database Lie
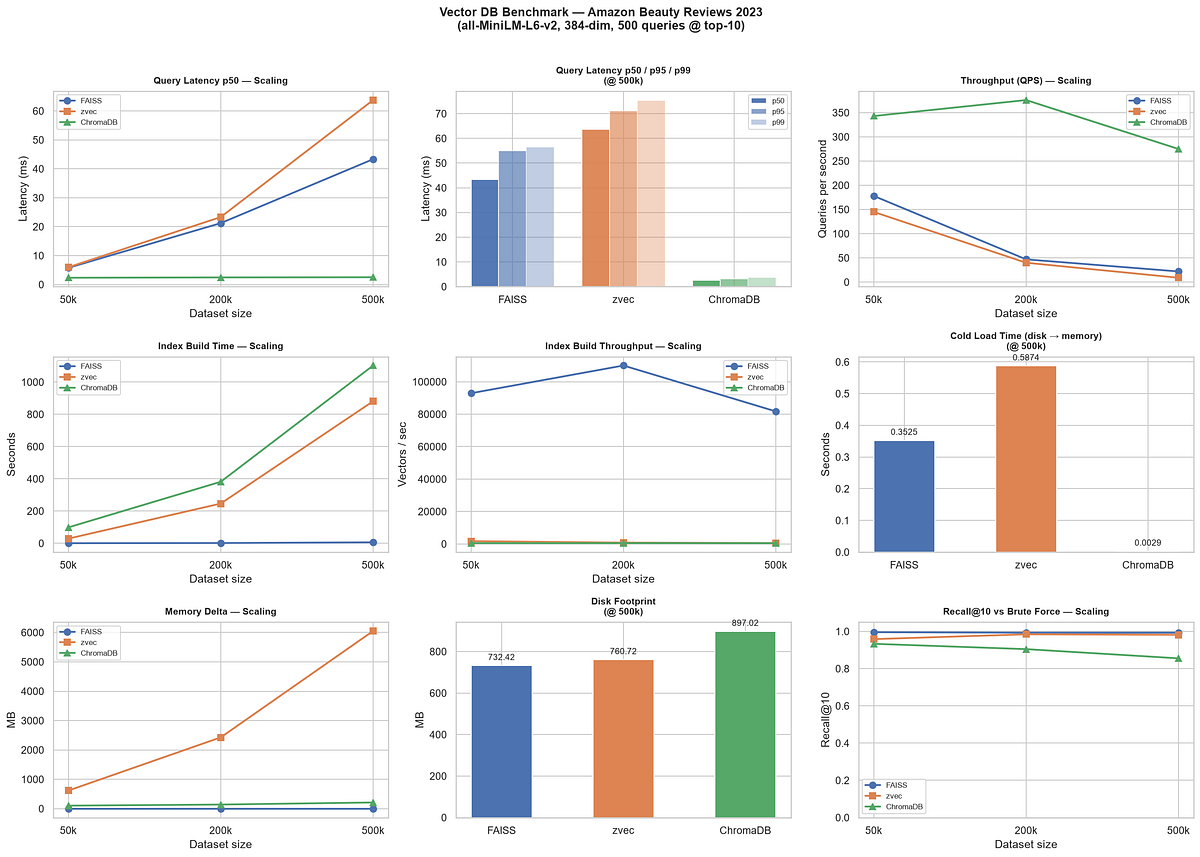
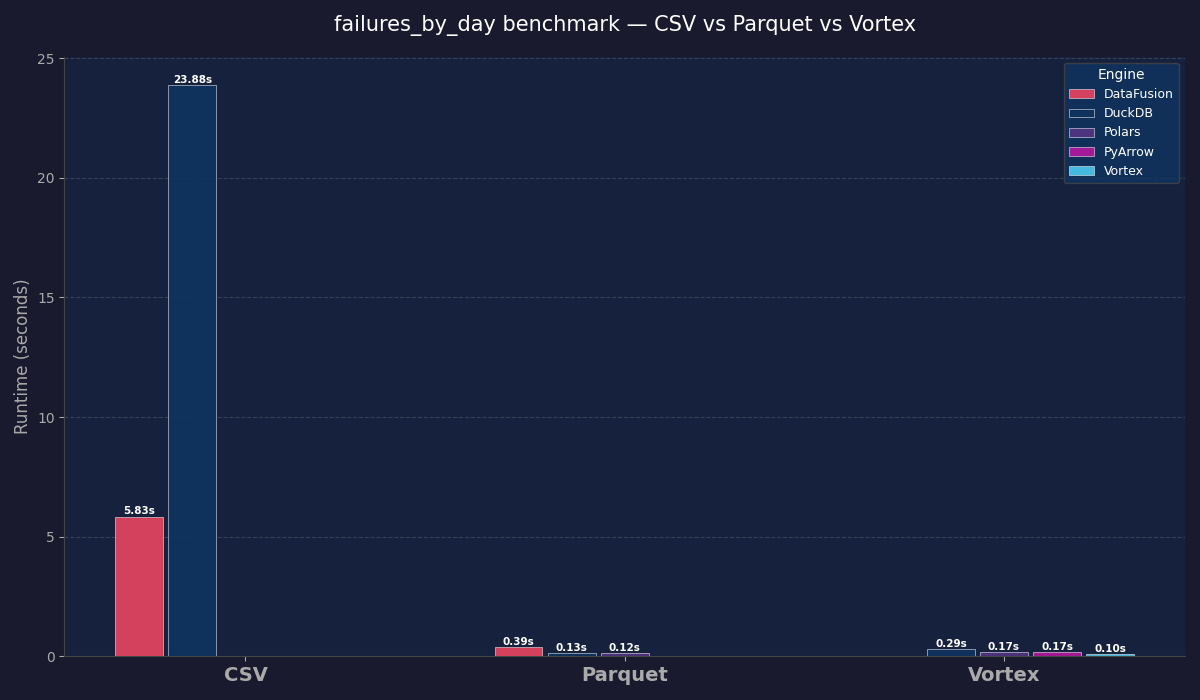
The Setup: The Hype Machine It’s vector database season. Conferences are full of RAG pipeline talks. Pinecone raised over $100 million; Milvus, Weaviate, and Qdrant are all well-fu...