aws.amazon.com
/1 month ago
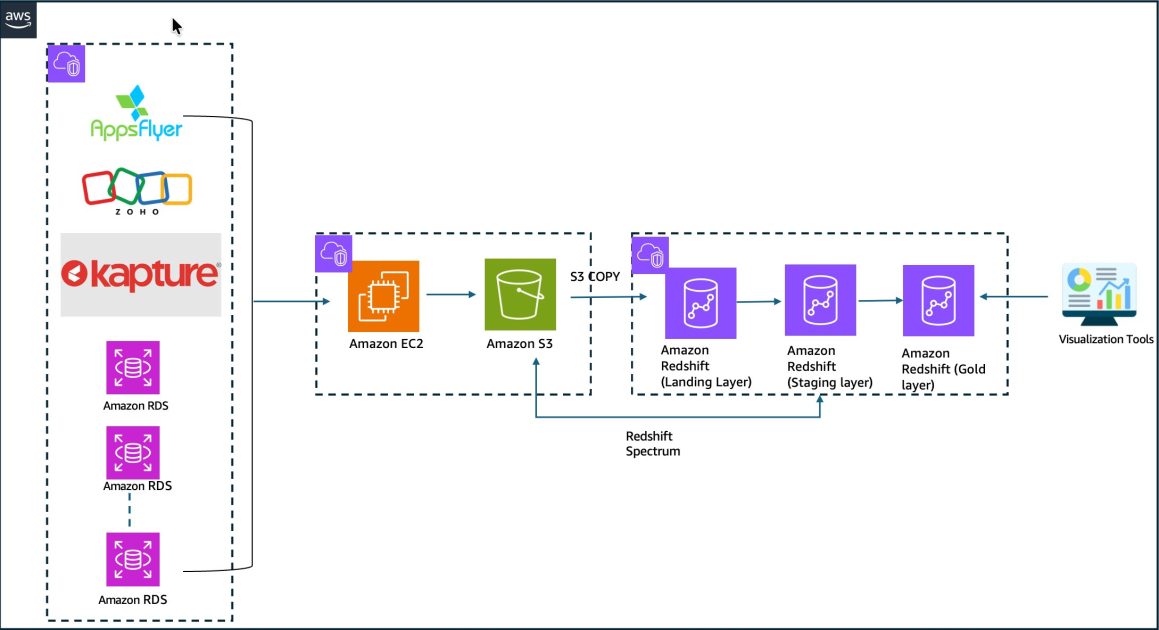
Real-time CDC from Aurora PostgreSQL to Amazon S3 Tables using Debezium and Firehose
In this post, we show you how to build a CDC pipeline that delivers query-ready Iceberg tables directly. The pipeline captures inserts, updates, and deletes from Aurora PostgreSQL...