
Latest updates for Reinforcement Learning
Fresh curated links around Reinforcement Learning are collected here so marketers can spot useful updates and turn timely ideas into posts faster.
Recent items include:
- How Reinforcement Learning Is Transforming Algorithmic Trading
- Reinforcement Learning from Scratch (Part 3): Policies, Value Functions, Bellman Equations, and…
- Temporal Difference Learning and Policy Gradient Optimization Fields: Engineering Native MQL5 Reinforcement Learning Arc
Post angles to try
Share the most useful takeaway for your audience.
Turn one article into a quick practical checklist.
Ask your audience how this shift affects their work.
Fresh articles and ideas
Recent curated links from global sources. Generate one free draft from any story, then use SocialBu to schedule and refine your content calendar.
medium.com
/2 weeks ago
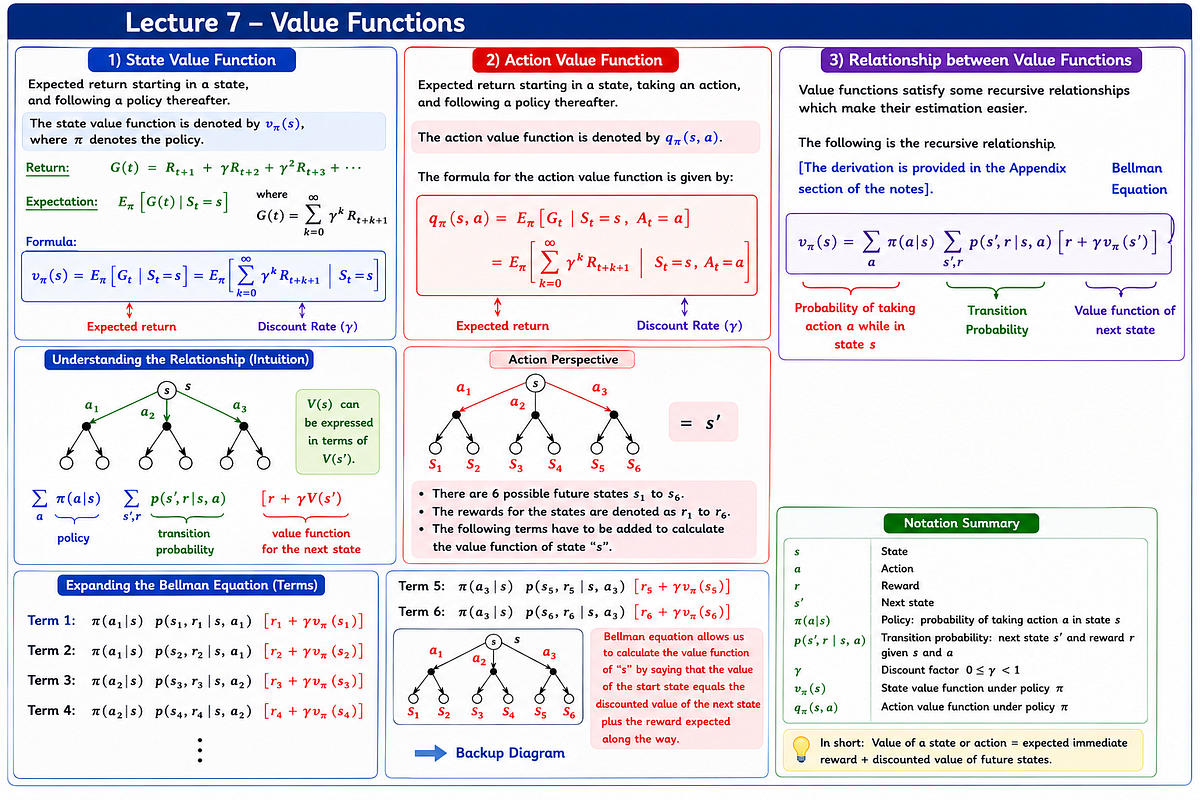
Reinforcement Learning from Scratch (Part 3): Policies, Value Functions, Bellman Equations, and…
In the previous article, we learned how Markov Decision Processes (MDPs) model sequential decision-making problems. Now, the next question…Continue reading on Medium »
mql5.com
/2 weeks ago
Temporal Difference Learning and Policy Gradient Optimization Fields: Engineering Native MQL5 Reinforcement Learning Arc
towardsdatascience.com
/1 month ago
The Fundamental Choice in Reinforcement Learning: On‑Policy vs. Off‑Policy
How a simple choice shapes exploration, safety, and efficiency The post The Fundamental Choice in Reinforcement Learning: On‑Policy vs. Off‑Policy appeared first on Towards Data Sc...
medium.com
/1 month ago
A very simple explanation of The Gambler’s Problem in Reinforcement Learning
This article is based on Example 4.3 from Sutton and Barto’s Reinforcement Learning: An Introduction, one of the most widely read…Continue reading on Medium »

aws.amazon.com
/1 week ago
Best practices for multi-turn reinforcement learning in Amazon SageMaker AI
In this post, we share best practices for reliable multi-turn RL training. We cover how to build a training environment you can trust, set up an external evaluation, design a rewar...

ujangriswanto08.medium.com
/1 week ago
A Practical Guide to Implementing the REINFORCE Algorithm in Python (Part 5)
Learn how to build the REINFORCE algorithm from scratch using Python, PyTorch, and Gymnasium with a step-by-step, beginner-friendly…Continue reading on Medium »

salesforce.com
/1 month ago
Can Language Models Remember What They Learn?
Post-training methods (RLVR, On-policy distillation) are Episode-local Language models are getting better at learning from feedback during post-training. In reinforcement learning...
just-merwan.medium.com
/2 weeks ago
What Is a Markov Decision Process? How Machines Make Smart Decisions
AI Update & MoreContinue reading on Medium »
vmblog.com
/1 month ago
Bugcrowd launches Reinforcement Learning environments to help AI models learn real-world security skills
Bugcrowd announced the launch of Reinforcement Learning (RL) Environments, a new offering designed to help AI developers build models that
habr.com
/2 weeks ago
Ты сможешь! Введение в машинное обучение с подкреплением для программистов и не только
Почти весь код туториалов, который мне попадался в открытом доступе, с точки зрения кодирования, написан на уровне junior-программиста, что вполне закономерно, ведь все Data Scienc...
pandaily.com
/1 month ago
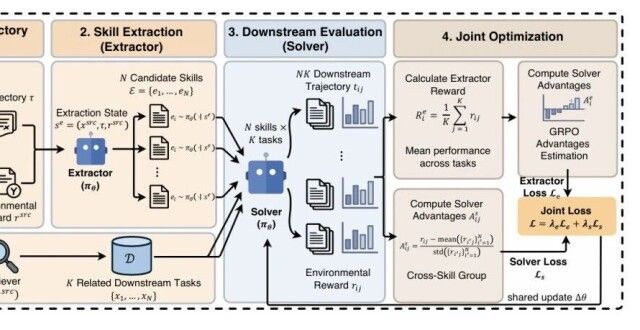
Xiaohongshu's Evolving-RL: A New Paradigm for Self-Evolving AI Agent Skills
Researchers from Xiaohongshu (RED), the influential Chinese lifestyle and social commerce platform, have published Evolving-RL, a novel reinforcement learning framework that enable...
r-bloggers.com
/1 month ago
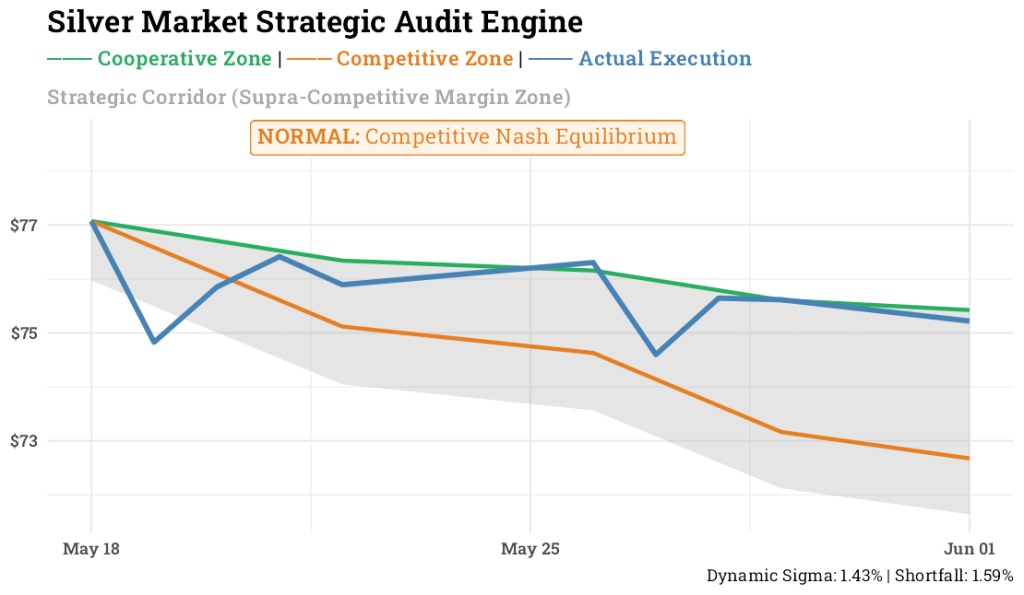
A Multi-Agent DDQN Strategic Audit Engine for Silver Markets using Keras/Tensorflow
1. Introduction & Theoretical Framework In modern electronic trading markets, algorithmic execution engines drive the vast majority of institutional order flows. Evaluating whe...
mql5.com
/2 weeks ago
Action Value Functional Variations and Bellman Optimality Fields: Embedding High Speed Q Learning Matrices for Native MQ

marktechpost.com
/2 weeks ago
DeepReinforce Releases Ornith-1.0: An Open-Source Coding Model Family That Learns Its Own RL Scaffolds
DeepReinforce released Ornith-1.0, an open-source coding model family built on Gemma 4 and Qwen 3.5. Instead of a fixed harness, the model learns its own scaffold during reinforcem...
journals.plos.org
/2 weeks ago
Delayed reward information is underweighted in reinforcement learning with dispersed feedback
by Miruna Cotet, David Poensgen, Ian Krajbich Learning is fundamental to adaptive behavior. In the typical learning task, each action is associated with only one outcome, which co...
towardsdatascience.com
/2 days ago
Agentic RAG: Let the Agent Search
A minimal OpenAI Agents SDK implementation where retrieval becomes a search-read-decide loop The post Agentic RAG: Let the Agent Search appeared first on Towards Data Science.
quantumcomputingreport.com
/5 days ago
Google Research Stabilizes “Willow” Quantum Processor Using Continuous Reinforcement Learning Control Layers
Overview of RL control. Google Quantum AI has introduced a hardware-control framework that unifies real-time calibration with active quantum error correction (QEC), allowing an aut...
Turn fresh research into a full content calendar
Use SocialBu to discover ideas, generate post drafts, and schedule them across your social channels.
Sources covering Reinforcement Learning
aws.amazon.com
Recent coverage from public sources
Public source
blogs.vmware.com
Recent coverage from public sources
Public source
habr.com
Recent coverage from public sources
Public source
journals.plos.org
Recent coverage from public sources
Public source
medium.com
Recent coverage from public sources
Public source
pandaily.com
Recent coverage from public sources
Public source