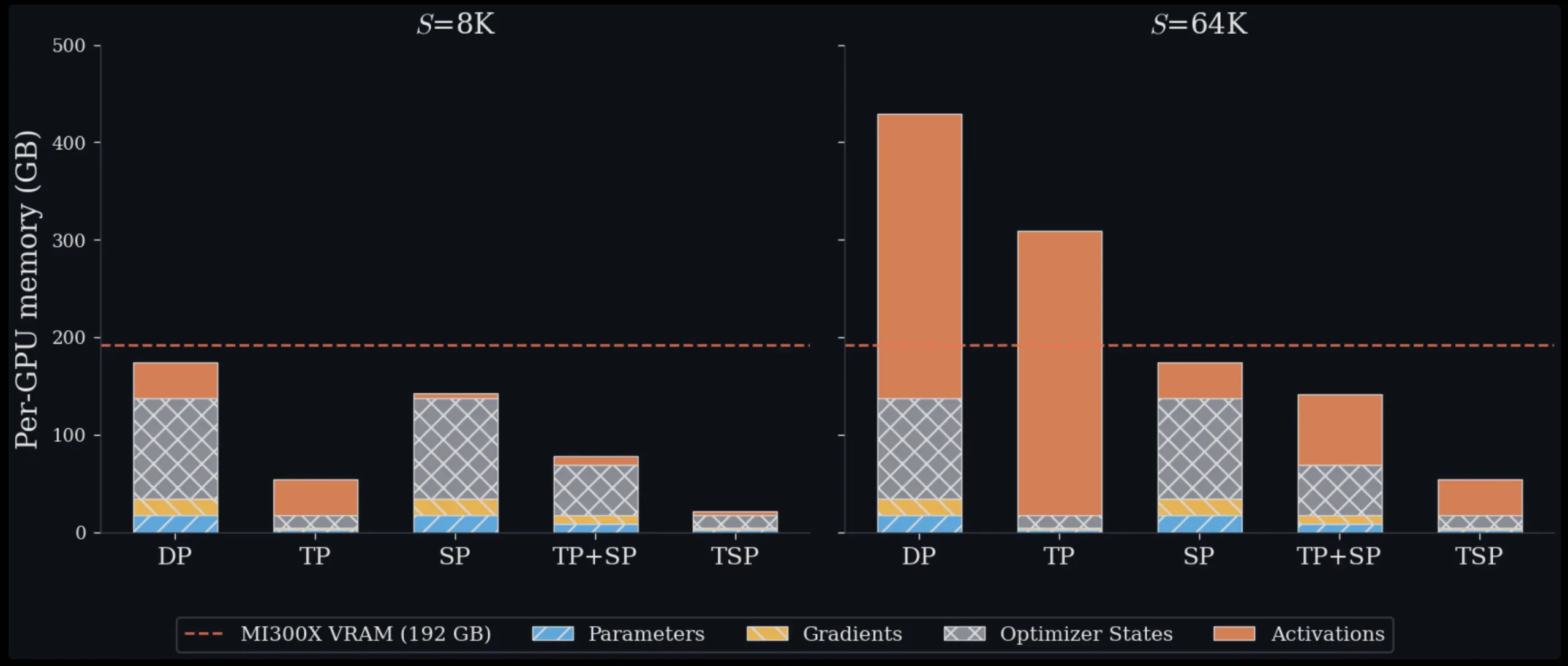
marktechpost.com
/1 week ago
Nous Research Releases Contrastive Neuron Attribution (CNA): Sparse MLP Circuit Steering Without SAE Training or Weight...
Nous Research releases Contrastive Neuron Attribution (CNA), a method that identifies and ablates sparse MLP neuron circuits to steer LLM behavior — no sparse autoencoder training,...