medium.com
/2 weeks ago
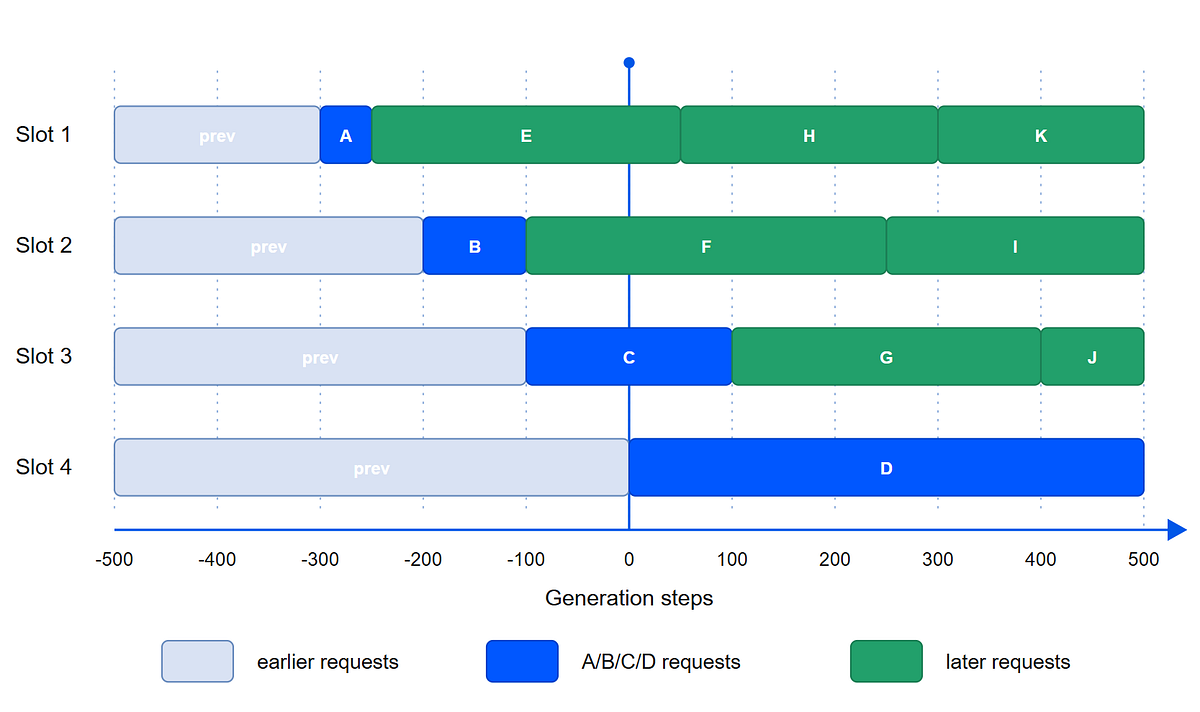
How vLLM Serves Thousands of Requests with Low Latency
Part 3 of the Understanding LLM Serving seriesContinue reading on Understanding LLM Serving »