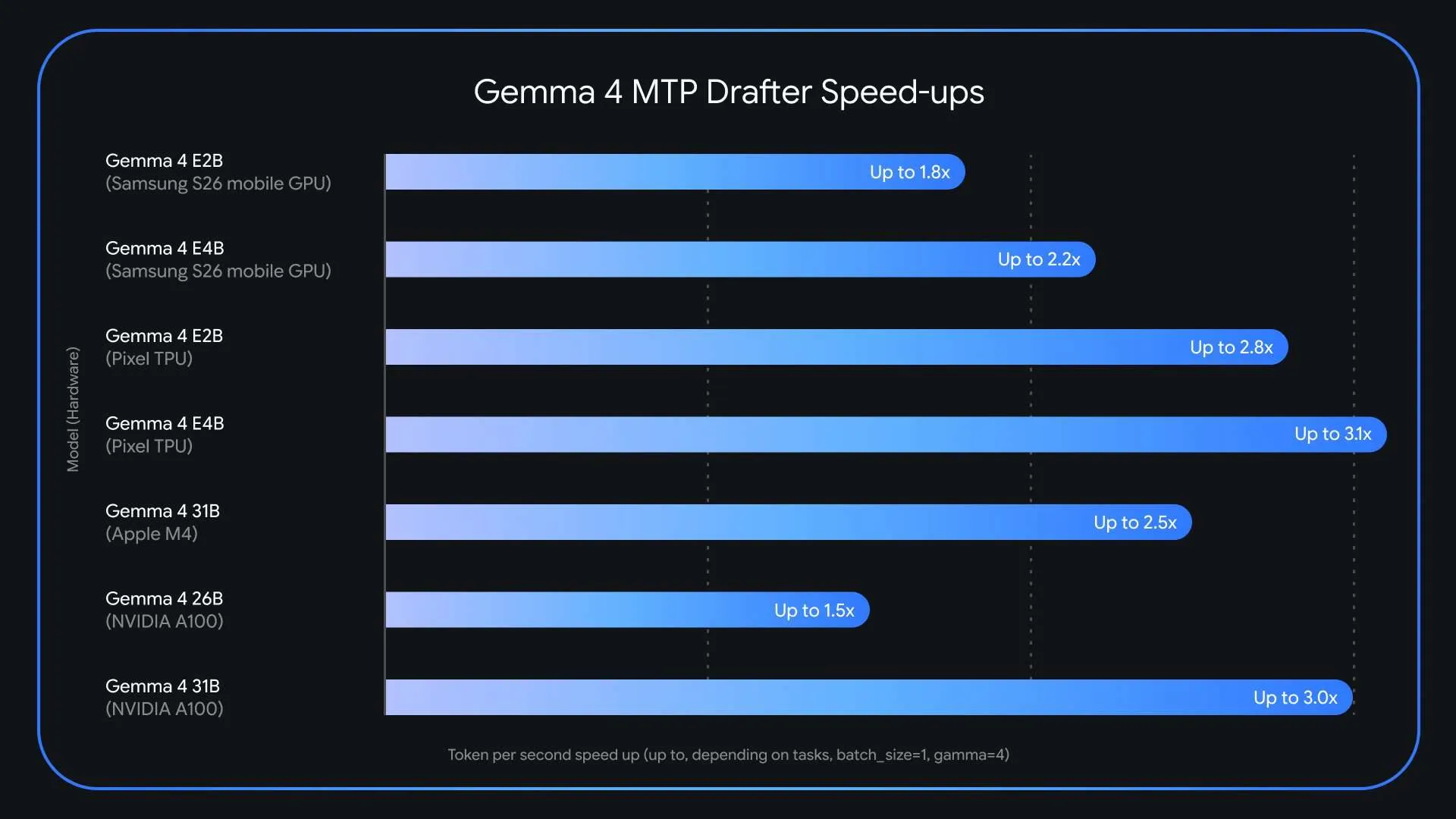
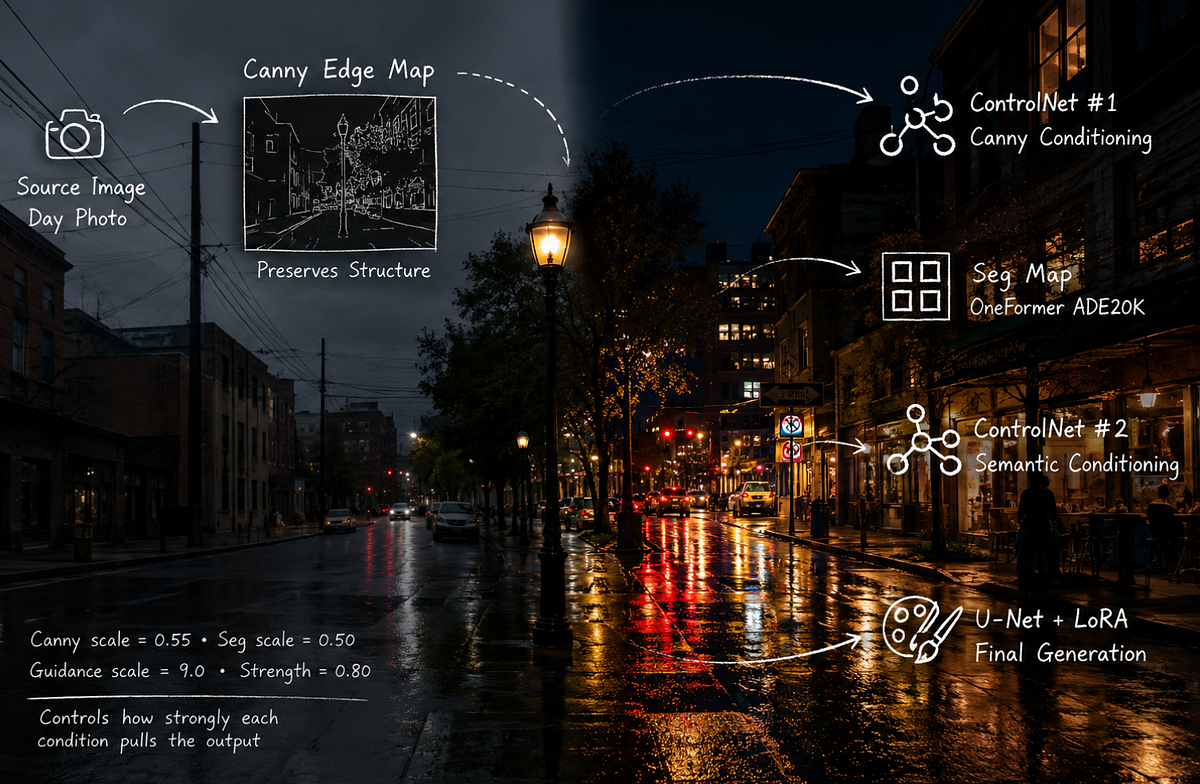
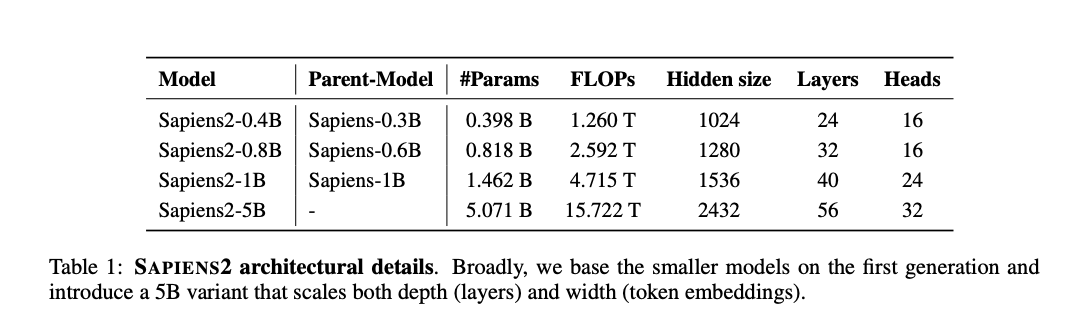
venturebeat.com
/3 days ago
MiniMax teases upcoming M3 model with new sparse attention mechanism and 15.6X long-context response speed boost
Among the many Chinese AI companies and laboratories vying for market share and attention (no pun intended) on the global marketplace, MiniMax stands out for its commitment to prov...