dzone.com
/3 weeks ago
KV Cache Implementation Inside vLLM
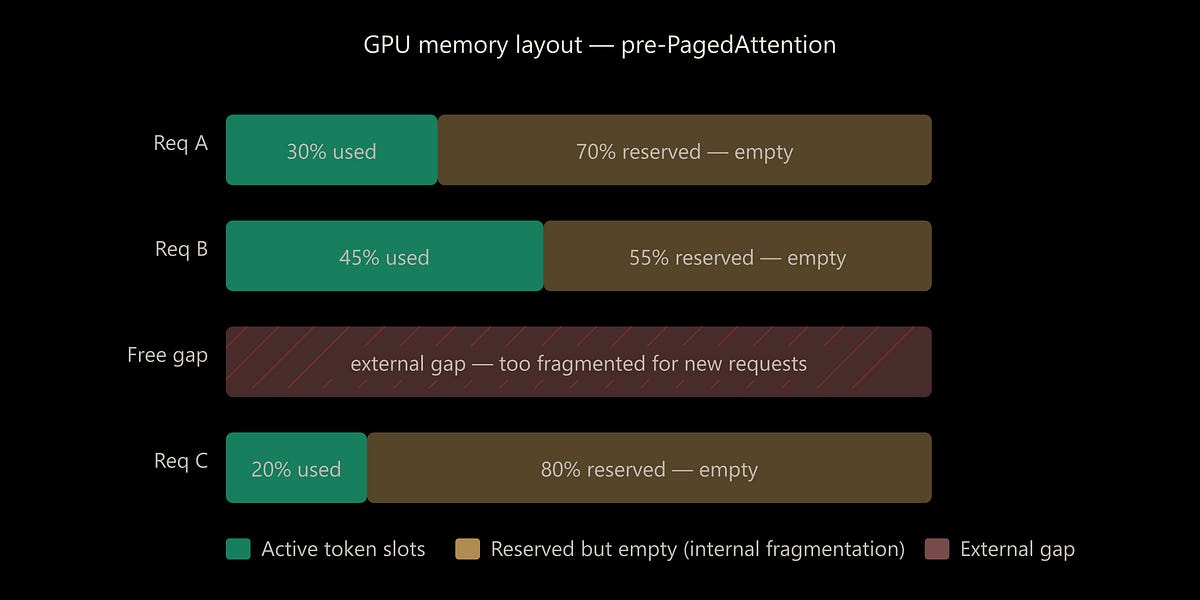
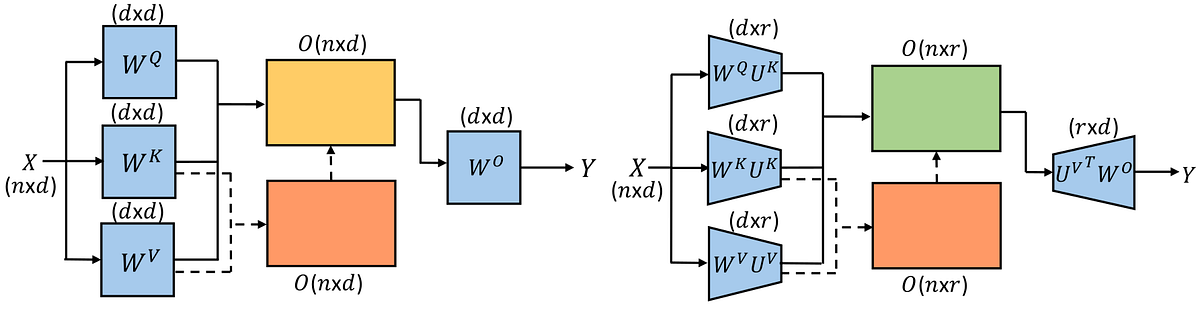
The key-value (KV) cache is a fundamental optimization in transformer-based LLM inference. It stores intermediate attention states, i.e., keys and values computed during the prefil...