dzone.com
/5 days ago
One Query, Four GPUs: Tracing a Distributed Training Stall Across Nodes
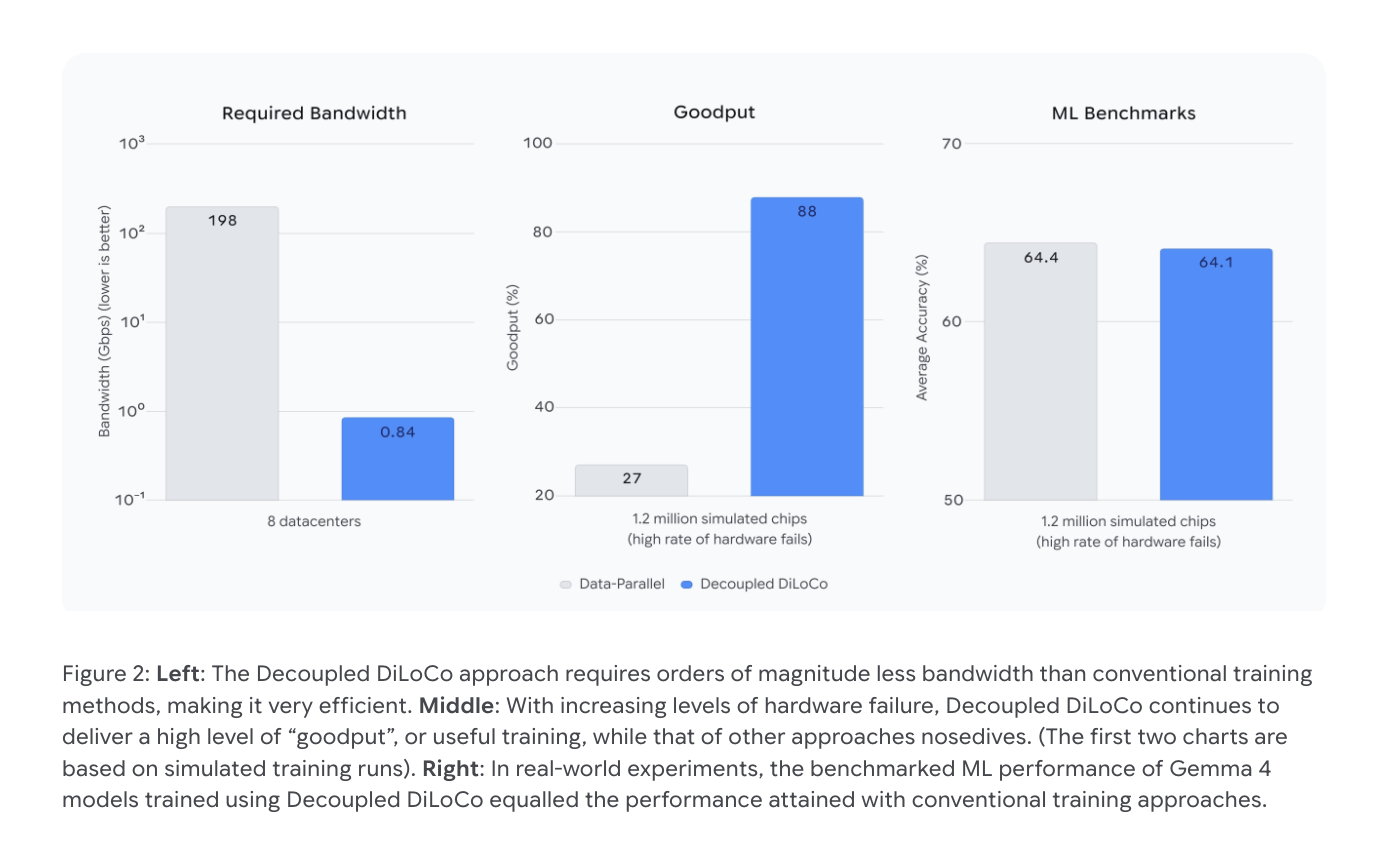
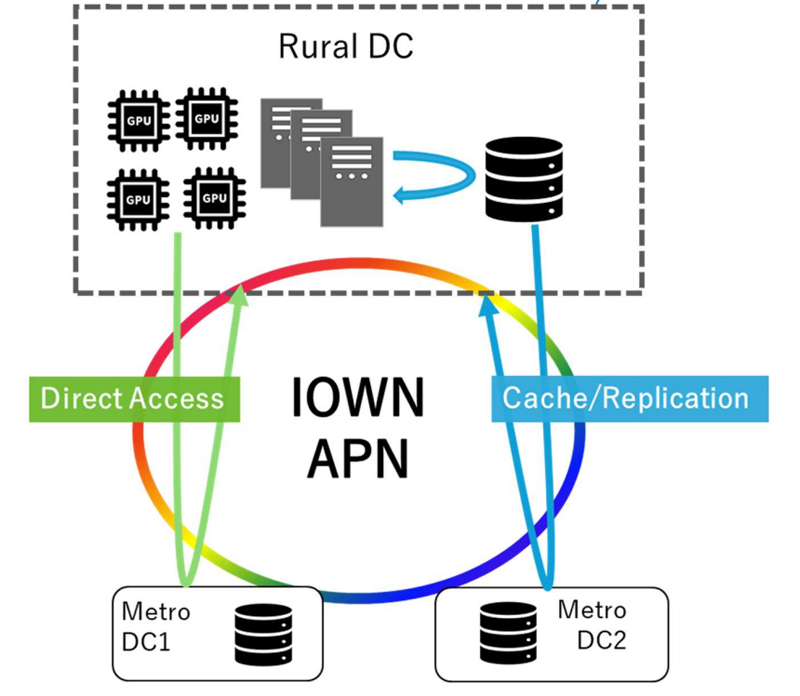
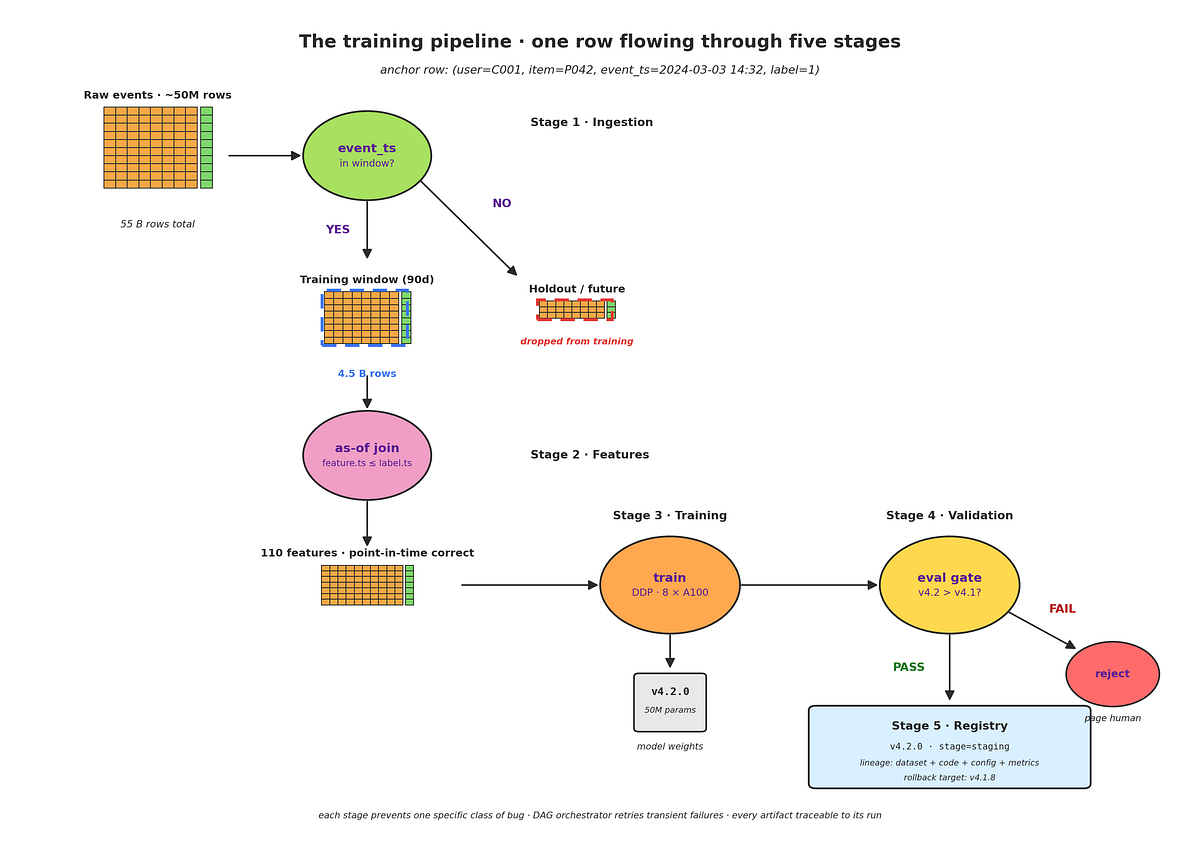
TL;DR A single straggling node held up a 4-node distributed training job. We found it by fanning out one SQL query to all four nodes and getting the answer in under a second. Thi...