marktechpost.com
/1 month ago
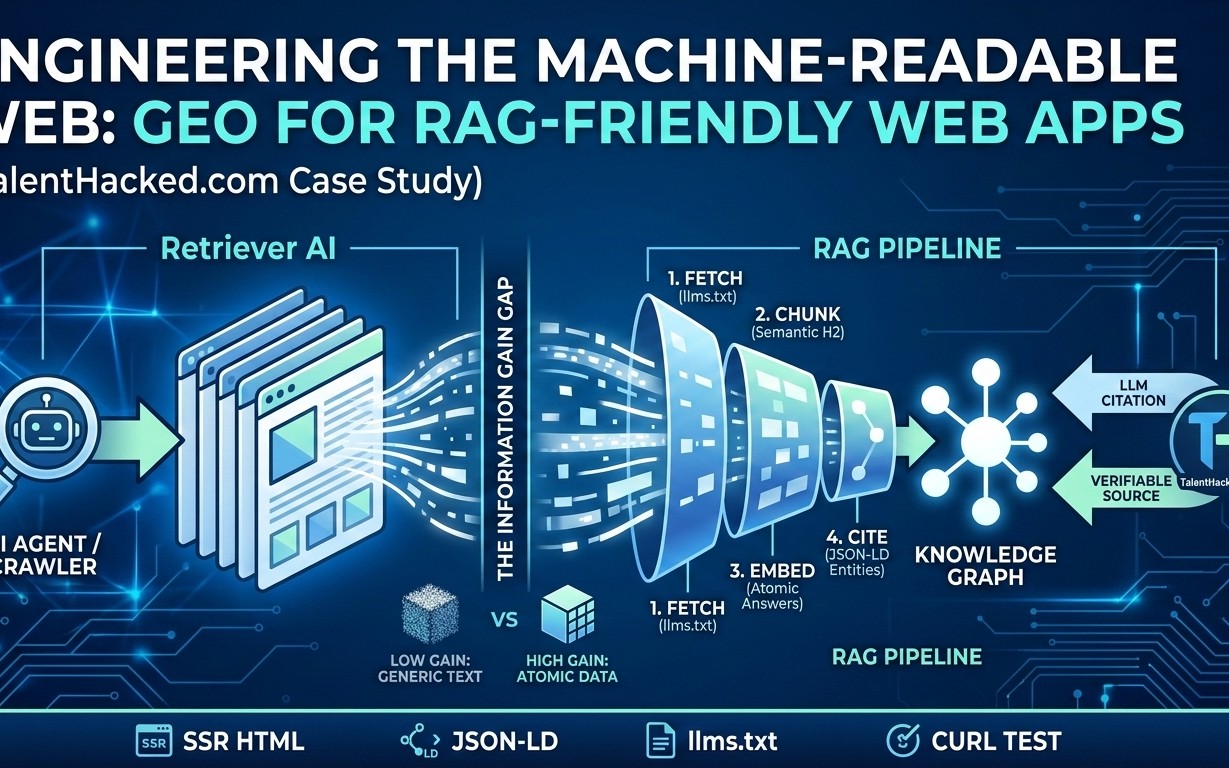
A Coding Implementation of Crawl4AI for Web Crawling, Markdown Generation, JavaScript Execution, and LLM-Based Structure...
In this tutorial, we build a complete and practical Crawl4AI workflow and explore how modern web crawling goes far beyond simply downloading page HTML. We set up the full environme...