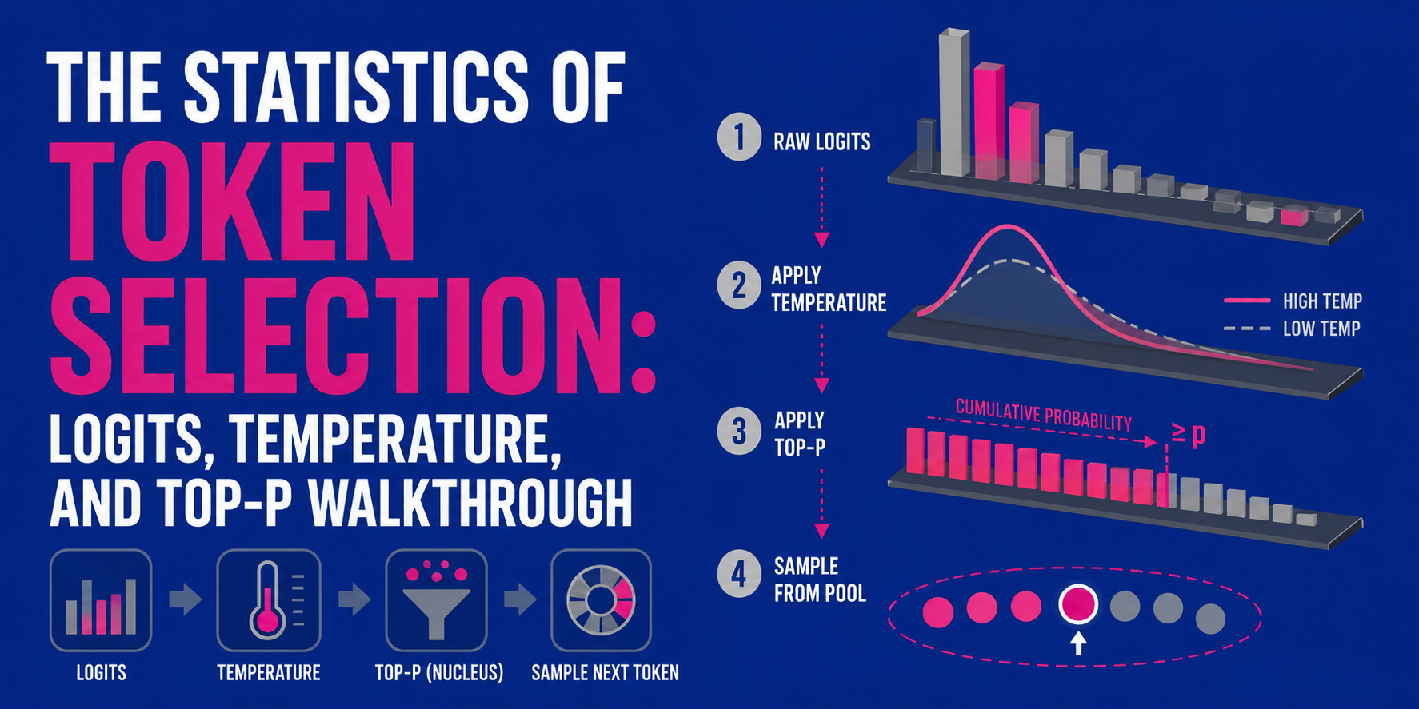
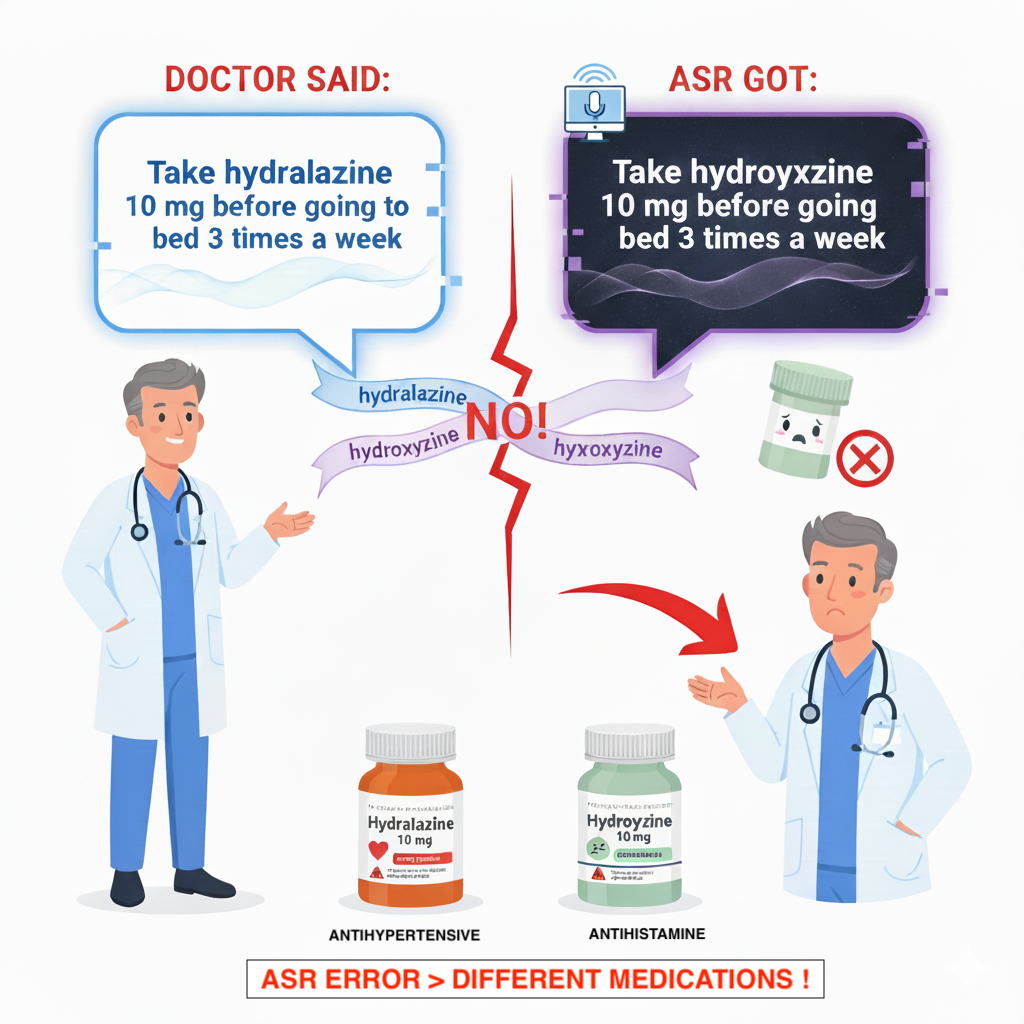
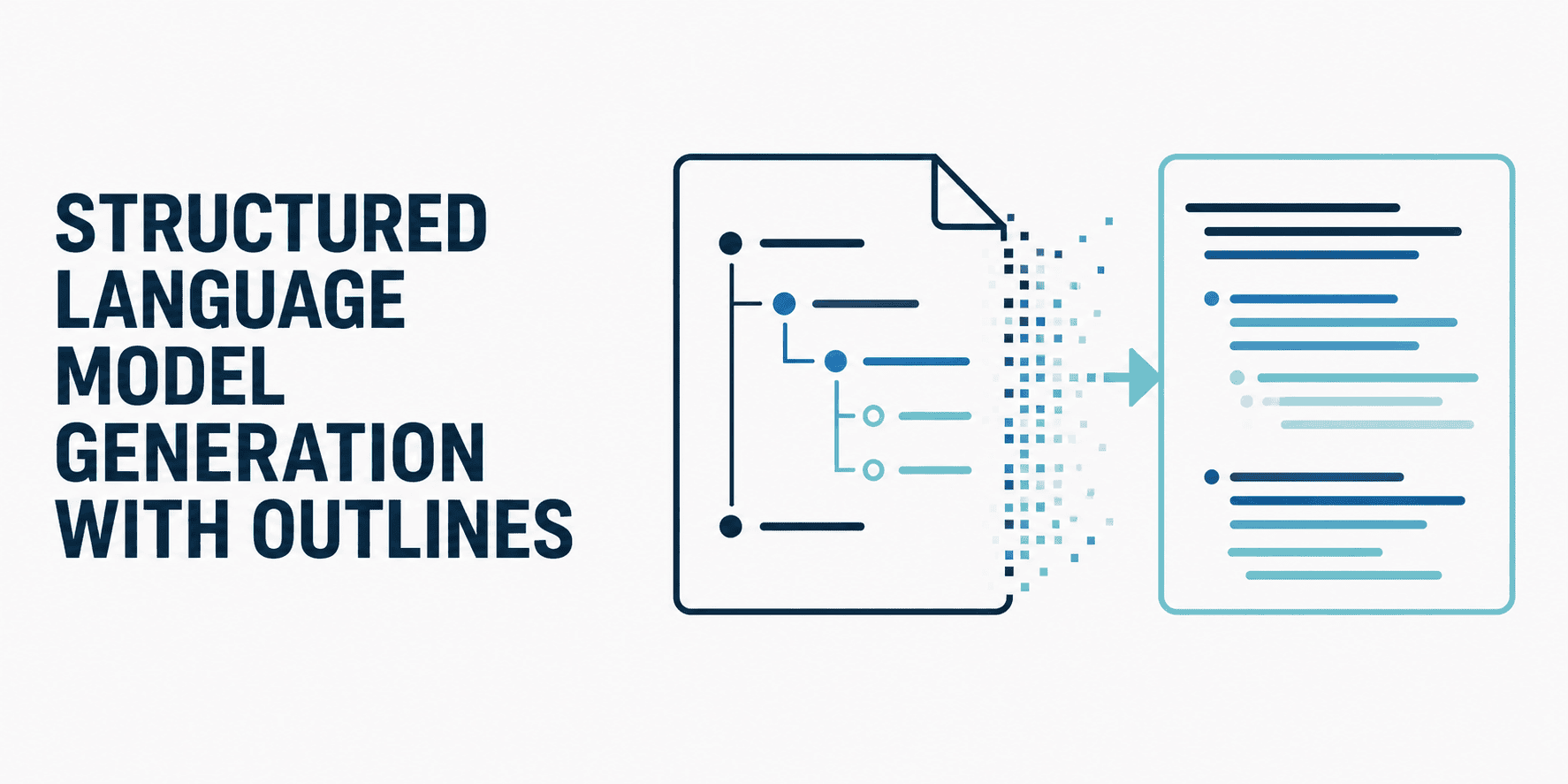
marktechpost.com
/1 week ago
Interfaze Ships diffusion-gemma-asr-small, an Open-Source Diffusion ASR Model Transcribing Six Languages via DiffusionGe...
Interfaze open-sourced diffusion-gemma-asr-small, a multilingual ASR model that transcribes via diffusion, not autoregression. It adds audio to Google's frozen DiffusionGemma using...