aws.amazon.com
/1 month ago
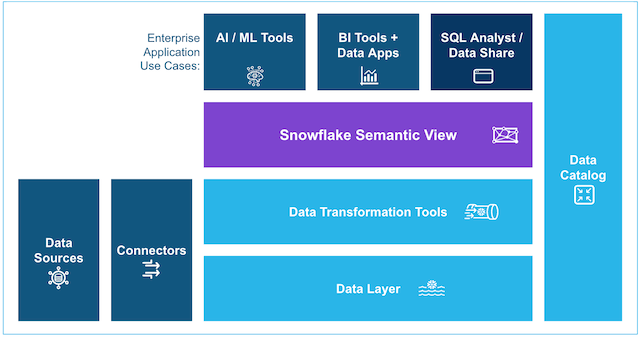
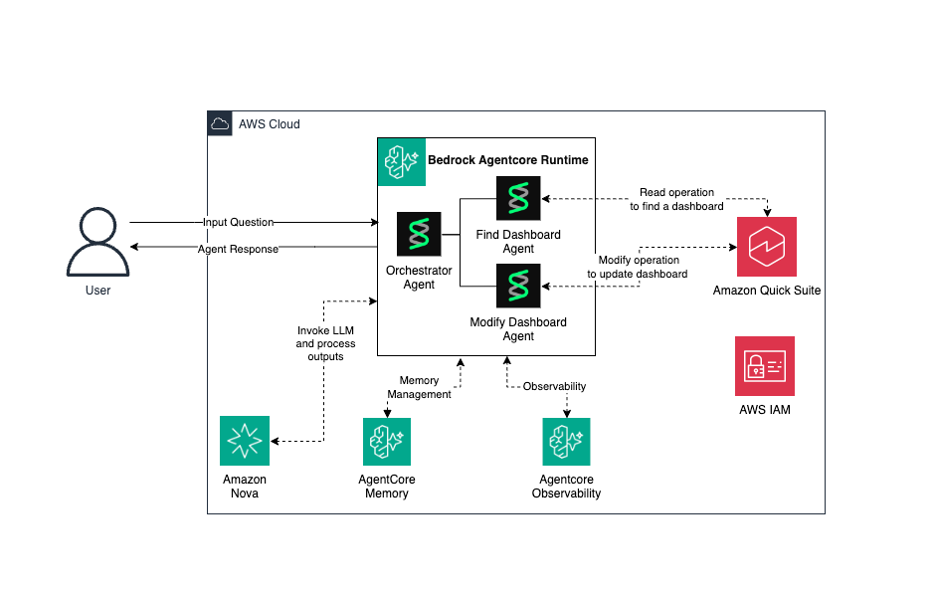
Automate data discovery and centralized management with AWS Glue Data Catalog
In this post, we show you how to tackle data discovery, classification, and governance across your databases, data warehouses, and object storage to regain visibility and control o...